A VP of Engineering signs a six-figure monitoring contract. The demo was impressive. Procurement checked every box. The deal closes.
Six months later, the platform is half-configured. Alert fatigue has set in. The on-call engineer spends 30% of their time maintaining the monitoring setup. When something breaks at 2 AM, the team still scrambles through war-room chaos.
Here’s the thing: the platform is working exactly as designed. That’s the problem.
This isn’t about bad tools. It’s about a structural gap between what was purchased and what was needed.
The Responsibility Boundary
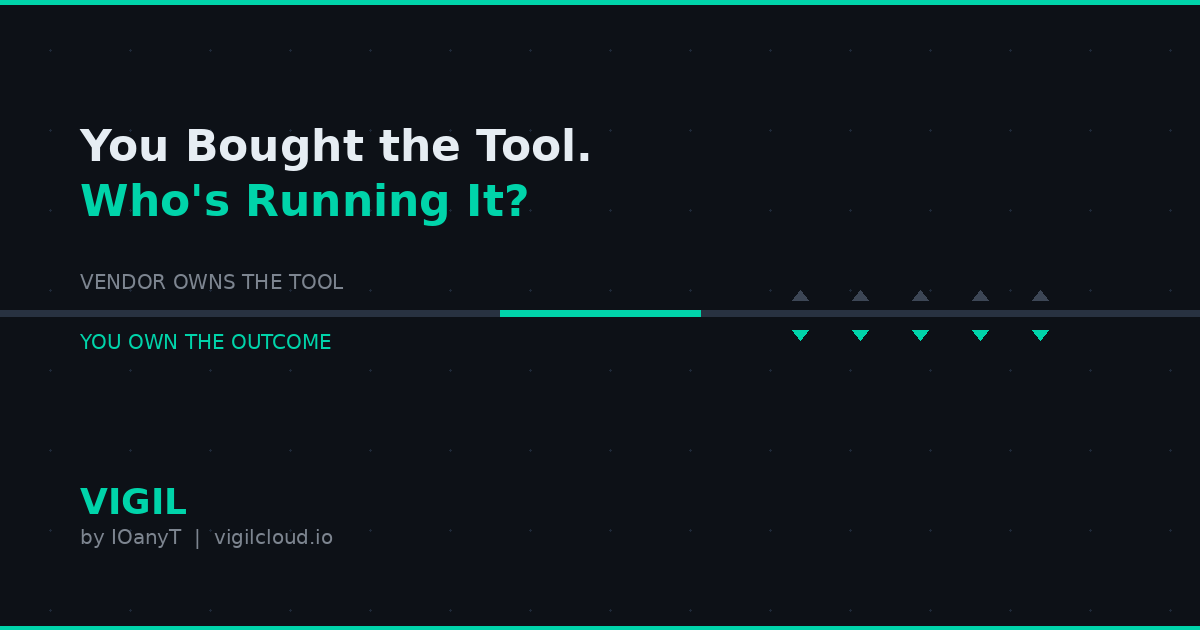
Every SaaS platform draws an invisible line. On one side: what the vendor owns. On the other: what’s yours to figure out.
What the vendor owns (for most monitoring tools):
- Data ingestion, storage, querying, visualization
- Alerting engine, API, integrations
- Platform availability, performance, security
What’s on you (the part that determines whether monitoring actually works):
- Deciding what to monitor
- Writing queries, setting thresholds
- Tuning alerts to signal real problems vs. noise
- Building runbooks
- Staffing on-call
- Waking up at 2 AM
- Diagnosing root cause
- Remediating
- Running the post-mortem
- Feeding lessons back into the system
The question most teams never ask until they’re deep in a contract: did we buy a solution, or did we buy more work? (A simple five-question diagnostic can tell you exactly where you stand.)
The vendor owns the tool. You own the outcome.
How We Got Here
Three forces shaped this dynamic, none of them malicious:
The breadth imperative. A platform serving 10,000 diverse customers can’t be opinionated about how any single one uses it. Flexibility becomes the product. Configuration surfaces multiply.
The checklist economy. Enterprise buyers send RFPs with 200 line items. Vendors ship features that survive procurement, not features that produce outcomes after deployment. The result: extraordinary capability, mediocre average utilization.
The talent assumption. Most platforms are architected for a customer with a dedicated platform engineering team and experienced SREs. That describes maybe 5% of companies. The other 95% are running lean teams where monitoring is everyone’s side job. The same assumption is now repeating itself with platform engineering and AIOps.
The gap isn’t in what these platforms can do. It’s in the distance between capability and realized value — and who’s expected to close that distance.
The Hidden Cost of “Self-Service”
The sticker price of a monitoring platform is the subscription. The real cost is everything around it.
Implementation cost: weeks or months of engineering time to instrument, configure, and establish alerting rules.
Maintenance cost: ongoing effort to keep monitoring in sync with evolving architecture.
Expertise cost: either hire specialists or accept the tool operates well below potential.
Cognitive load: every alert is a context switch. Every false positive erodes trust. Every 2 AM page pulls someone out of sleep — and the recovery cost in focus and productivity extends into the next day.
The compounding problem: companies end up needing a Datadog engineer to run Datadog. A PagerDuty specialist to tune PagerDuty. Each tool that was supposed to reduce operational burden generates its own operational burden. The stack grows. The team doesn’t. When you add up the tools, the engineers, and the hidden costs, the total often approaches $700K/year — and the CTO is still getting paged.
Every hour a senior developer spends tuning Prometheus alerts is an hour they’re not spending on the feature that moves the roadmap forward.
What “Managed” Actually Means
AWS “managed” RDS still requires schema design, query optimization, backup policies, failover testing, capacity planning. “Managed Grafana” means someone else runs the instances — not that someone else builds dashboards, writes alerting rules, or improves reliability.
Managing the tool and managing the function are fundamentally different offerings. Most SaaS falls into the first. Very little exists in the second.
| Tier | What it looks like | Who owns the outcome? |
|---|---|---|
| Tool | Datadog, Grafana, Prometheus | You |
| Managed tool | AWS managed Grafana, managed Prometheus | You (still) |
| Managed function | Someone owns dashboards, alerts, incident response, and improvement | The provider |
Redrawing the Line
The sharper question isn’t “did SaaS shift problems onto customers” — to some degree that’s inherent in any general-purpose tool. The question is: where should the responsibility boundary actually be?
Who the current model works for: the small percentage of organizations with large, experienced platform teams. They have the people, processes, and institutional knowledge to extract full value.
Who it doesn’t work for: the vast majority — real production systems, lean teams that need to ship product, not babysit infrastructure. For them, there’s a permanent gap between the monitoring they’ve purchased and the reliability they’ve achieved.
What closing that gap requires: moving the responsibility boundary. Not just managing the platform, but managing what the platform is supposed to accomplish — meaningful observability, actionable alerts, fast incident response, continuous improvement.
Think of it this way: when a company hires an accounting firm, they don’t also hire internal accountants to make the firm’s work useful. When a company retains outside counsel, they don’t need a legal operations team to operationalize the advice. Infrastructure monitoring somehow became the exception.
The Outcome Layer
What it is: the operational intelligence and human accountability that sits between a monitoring platform and actual reliability.
How it works: the monitoring tool provides the data. The outcome layer provides the judgment — what matters, what’s noise, what needs a human now vs. what can wait, and what systemic changes would prevent this alert from firing again.
What it’s not: replacing engineering team expertise. It’s freeing that expertise for the work that actually differentiates the business.
What if monitoring worked the way every other professional service works? You define the outcome — reliable systems, fast incident response, continuous improvement — and someone takes accountability for delivering it. They bring the tools, the expertise, the processes, and the willingness to carry the pager.
The Shift
This isn’t a radical idea. Just one the industry hasn’t fully embraced yet.
Vigil by IOanyT is built on this thesis. We own the tools, the configuration, the alert tuning, the incident response, and the 2 AM pages. Your engineers focus on building what matters.
Monitoring as a solved problem, not an ongoing project.


